※ 이 글은 모두의 데이터 분석 with 파이썬 책의 예제를 연습한 내용입니다.
1. 프로젝트 구상하기
전국에서 삼성1동의 연령별 인구 구조와 가장 형태가 비슷한 지역은 어디일까?
위 질문에 답하기 위해 어떻게 데이터를 갖고 와서 코드로 나타낼지를 생각해야 한다. 먼저 인구 데이터는 지난번 인구 공공데이터 시각화 글에서 가져왔었다.
2020/05/08 - [데이터 분석/데이터분석 연습] - 인구 공공데이터 시각화하기
인구 공공데이터 시각화하기
※ 이 글은 모두의 데이터 분석 with 파이썬 책의 예제를 연습한 내용입니다. 1. 인구 공공데이터 내려받기 행정안전부 홈페이지(www.mois.go.kr) 접속 후 정책자료 > 통계 > 주민등록 인구통계를 클릭�
memoir-of-experience.tistory.com
데이터를 읽어온 다음 찾고자 하는 지역명을 넣었을 때 해당 지역의 인구 구조가 나올 것이고, 이 인구 구조와 가장 비슷한 인구 구조를 가진 지역을 찾아 시각화 하면 된다.
2. 알고리즘을 코드로 표현하기
데이터를 읽어온다
헤더를 제외한 인구 데이터를 row로 출력한다.
import csv
f = open('age.csv')
data = csv.reader(f)
next(data)
for row in data:
print(row)궁금한 지역의 이름을 받는다.
입력 값을 받는 함수는 input이다. name 객체에 지역 이름을 받는다.
name = input('인구 구조가 알고 싶은 지역의 이름(읍면동)을 입력해주세요: ')궁금한 지역의 인구 구조를 저장한다.
인구 데이터를 row 기준으로 반복문을 만들고 numpy 라이브러리를 이용해 데이터를 배열에 담는다. 여기서 dtype은 data type으로 데이터 타입을 정수로 변환하는 옵션이다.
import csv
import numpy as np
f = open('age.csv')
data = csv.reader(f)
next(data)
name = input('인구 구조가 알고 싶은 지역의 이름(읍면동)을 입력해주세요: ')
for row in data:
if name in row[0]:
home = np.array(row[3:], dtype=int)
print(home)저장된 데이터를 시각화하면 다음과 같다.
import matplotlib.pyplot as plt
plt.rc('font', family = 'Malgun Gothic')
plt.title(name + '지역의 인구구조')
plt.plot(home)
plt.show()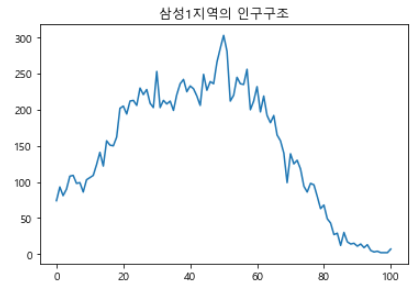
지역별 인구수가 다르기 때문에 인구수보다는 연령별 인구 비율을 비교하는 것이 좋다. row[2]는 해당 지역의 전체 인구수로 ','이 있어 int로 바로 변경되지 않으므로, age.csv에서 모든 데이터를 통화 > 일반으로 변경한다.
import csv
import numpy as np
f = open('age.csv')
data = csv.reader(f)
next(data)
name = input('인구 구조가 알고 싶은 지역의 이름(읍면동)을 입력해주세요: ')
for row in data:
if name in row[0]:
home = np.array(row[3:], dtype=int) / int(row[2])
print(home)특정 지역의 0세 인구 비율과 비교한다.
지역을 비교하기 위해 away 객체를 생성한다. home에서 away를 뺀 값을 출력하면 연령별로 인구비율의 차이가 나온다. 그 차이의 합계를 numpy의 sum 함수로 구하면 다음과 같다.
import csv
import numpy as np
f = open('age.csv')
data = csv.reader(f)
next(data)
data = list(data)
name = input('인구 구조가 알고 싶은 지역의 이름(읍면동)을 입력해주세요: ')
for row in data:
if name in row[0]:
home = np.array(row[3:], dtype=int) / int(row[2])
for row in data:
away = np.array(row[3:], dtype=int) / int(row[2])
print(np.sum(home - away))
모든 지역에 반복해서 연령별 인구비율 차이의 최솟값을 구한다. 찾고자 하는 지역의 인구비율을 home에 저장한 뒤 전체 지역의 인구비율을 away에 저장해 차이값의 합계를 s 객체에 저장한다. 여기에 최솟값을 구하기 위해 mn, result_name, result 세 가지 객체를 추가로 생성했다. mn은 최솟값을 저장하고 result_name은 최솟값을 가진 지역이름을 저장한다. result는 최솟값을 가진 지역의 연령대별 인구비율을 저장한다. for문과 if문을 이용해 이 과정을 반복하면서 최솟값을 가진 지역을 찾는다.
import csv
import numpy as np
f = open('age.csv')
data = csv.reader(f)
next(data)
data = list(data)
name = input('인구 구조가 알고 싶은 지역의 이름(읍면동)을 입력해주세요: ')
mn = 1
result_name = ''
result = 0
for row in data:
if name in row[0]:
home = np.array(row[3:], dtype=int) / int(row[2])
for row in data:
away = np.array(row[3:], dtype=int) / int(row[2])
s = np.sum(home - away)
if s < mn:
mn = s
result_name = row[0]
result = away
이를 시각화하면 다음과 같다.
import matplotlib.pyplot as plt
plt.plot(home)
plt.plot(result)
plt.show()
그래프에 제목과 범례를 넣으면 두 지역을 명확히 표시할 수 있다.
import matplotlib.pyplot as plt
plt.rc('font', family = 'Malgun Gothic')
plt.title(name + '지역과 가장 비슷한 인구구조를 가진 지역')
plt.plot(home, label = name)
plt.plot(result, label = result_name)
plt.legend()
plt.show()
여기서 이상한 점을 발견할 수 있다. 원래대로라면 특정 지역과 전체 지역을 비교하면 특정 지역이 전체 지역에 속하기 때문에 동일한 그래프가 나와야 한다. 예상과 다른 이유는 최소값을 찾는 코드에서 인구비율의 차이에 음수값이 생기기 때문이다. 음수값을 보정해 0에 가까운 지역을 찾으려면 s값을 제곱하면 된다. 수정한 코드는 다음과 같다.
import csv
import numpy as np
f = open('age.csv')
data = csv.reader(f)
next(data)
data = list(data)
name = input('인구 구조가 알고 싶은 지역의 이름(읍면동)을 입력해주세요: ')
mn = 1
result_name = ''
result = 0
for row in data:
if name in row[0]:
home = np.array(row[3:], dtype=int) / int(row[2])
for row in data:
away = np.array(row[3:], dtype=int) / int(row[2])
s = np.sum((home - away)**2)
if s < mn:
mn = s
result_name = row[0]
result = away
이제 동일한 지역을 제외하는 코드를 작성하면 완성된다(name not in row[0]).
import csv
import numpy as np
f = open('age.csv')
data = csv.reader(f)
next(data)
data = list(data)
name = input('인구 구조가 알고 싶은 지역의 이름(읍면동)을 입력해주세요: ')
mn = 1
result_name = ''
result = 0
for row in data:
if name in row[0]:
home = np.array(row[3:], dtype=int) / int(row[2])
for row in data:
away = np.array(row[3:], dtype=int) / int(row[2])
s = np.sum((home - away)**2)
if s < mn and name not in row[0]:
mn = s
result_name = row[0]
result = away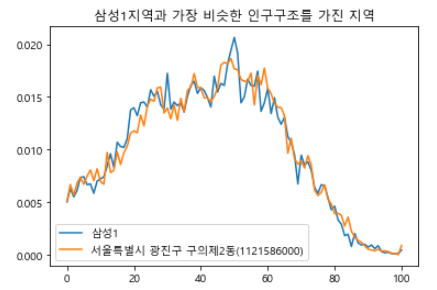
그래프를 살펴보면 삼성1 지역과 유사한 인구구조를 가진 지역은 구의제2동인 것을 확인할 수 있다.
'데이터 분석 > 데이터분석 연습' 카테고리의 다른 글
| pandas 라이브러리 활용한 데이터 분석 (0) | 2020.05.16 |
|---|---|
| numpy 라이브러리 활용하기 (0) | 2020.05.14 |
| 지하철 시간대별로 데이터 시각화 (2) | 2020.05.11 |
| 대중교통 데이터 시각화하기 (1) | 2020.05.10 |
| 동네 구조 파이차트와 산점도로 나타내기 (0) | 2020.05.09 |




댓글